vector 클래스 내부에도
iterator 클래스가 구현되어 있습니다.
아래 코드에서
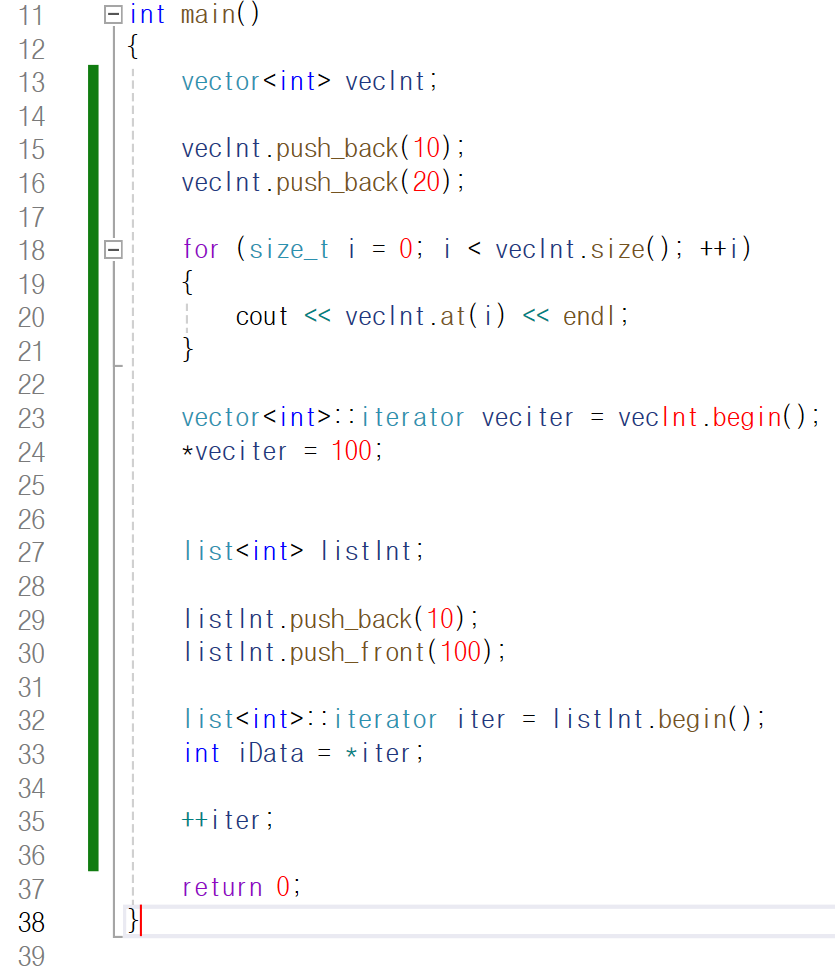
23번째 줄을 보시면
vector의 int 버전 클래스 내부에 있는
iterator 클래스를 통해 객체 veciter를 만들었습니다.
그리고 veciter에 vecInt가 가리키는 가변 배열의
주솟값을 대입했죠.
veciter가 가리키는 공간에
* 연산을 통해 100을 대입할 수 있습니다.
vecInt가 가리키는 가변 배열의 주솟값이
저장된 veciter에 바로 * 연산을 통해 100을
대입하면 가변 배열의 0번째 인덱스에
100이 대입될 것입니다.
0번째 인덱스가 아닌
1번째 인덱스에 100을 넣고 싶다면
++veciter 코드를 추가한 후 대입하면 됩니다.
veciter는 0번째 인덱스를 가리키고 있으므로
값을 하나 올리면 다음 인덱스를 가리키게 됩니다.
이후 * 연산을 통해 veciter에 100을 대입하면 되겠죠.

35번째 줄에서 볼 수 있듯이
vector뿐만 아니라 list에서도 똑같이 작동합니다.
vector는 가변 배열이므로 연속적인 메모리 형태를 하고 있고
list는 리스트이므로 각 데이터가 모두 떨어져 있는 형태입니다.
이렇게 두 자료 구조의 구조가 다름에도
같은 문법을 통해 iterator를 사용할 수 있는 이유는
vector, list와 같은 자료 구조 클래스 내부에
iterator라는 inner 클래스를 다 구현했기 때문에
서로 다르게 작동하는 자료 구조지만 같은 이름의
iterator 클래스를 사용할 수 있으며 같은 문법으로 사용할 수 있는 것이죠.
근데 가변 배열 역할을 하는 vector는
at 함수나 [ ] 연산자를 통해 각 인덱스에 접근이 가능합니다.
따라서 vector 클래스 내부에 존재하는
iterator 클래스를 통해 객체를 만들고
해당 객체를 통해 가변 배열의 주솟값을 받아
인덱스에 접근하는 것은 비효율적으로 보입니다.
하지만 이러한 과정이 마냥 비효율적이라고 할 수는 없습니다.
아래 그림처럼
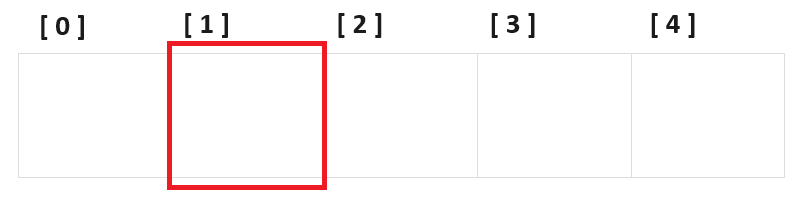
가변 배열이 있을 때 1번 인덱스의 데이터를 삭제한다고 합시다.
삭제한 후에 그냥 빈 공간으로 두면 문제가 발생합니다.
왜냐하면 가변 배열에 push_back 함수를 통해 데이터를 삽입하면
현재 데이터의 개수를 나타내는 iCount를 통해 인덱스에 접근하고,
데이터를 넣죠?
처음 위 가변 배열의 iCount의 값은 5일 것입니다.
그리고 1번 인덱스의 값을 삭제했으니
iCount의 값은 4가 되겠죠.
이후 push_back 함수를 통해 값을 넣으려고 하면
가변배열[4] 이렇게 접근하여 값을 넣을 것입니다.
하지만 1번 인덱스의 데이터를 삭제한 후에
그냥 두었기 때문에 4번 인덱스에는 값이 그대로 있습니다.
이미 값이 있는 공간에 새로운 값을 덮어쓰게 되어
문제가 발생하죠.
그래서 값을 삭제하면
뒤에 있는 값을 앞으로 옮기는 동작이 필요합니다.
특정 위치에 있는 데이터를 삭제하는 함수를 만드려면
몇 번째 데이터를 삭제할 것인지 알려 줘야 할 것입니다.
그럼 예상해 보면
delete(), remove() , erase() 등의 키워드에다가
소괄호 안에 숫자를 넣어 몇 번째인지 알려 주면 될 것 같죠?
그래서 가변 배열을 가리키는 객체 vecInt를 통해
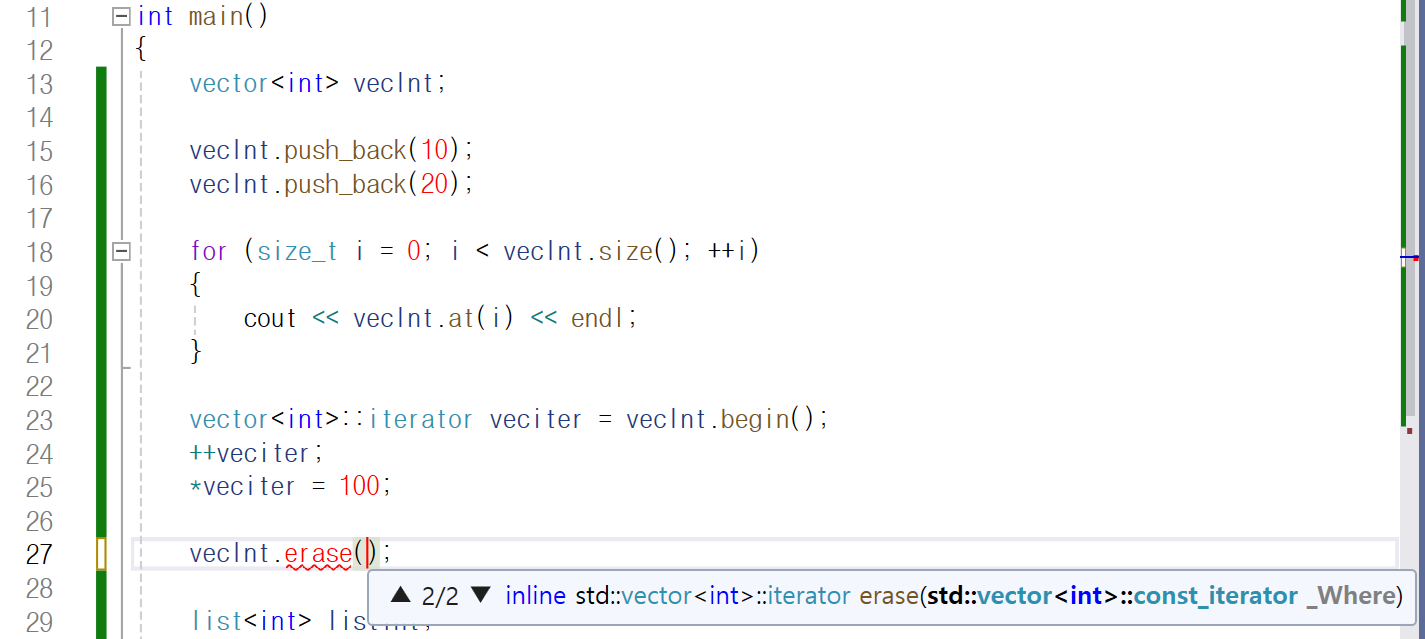
멤버 함수를 찾아 보니 erase라는 함수가 보입니다.
근데 인자로 무엇을 달라고 요청하는지 보니,
iterator를 달라고 하네요.
그리고 이를 _Where라는 매개 변수에
저장하도록 만들어졌습니다.
아래 그림처럼
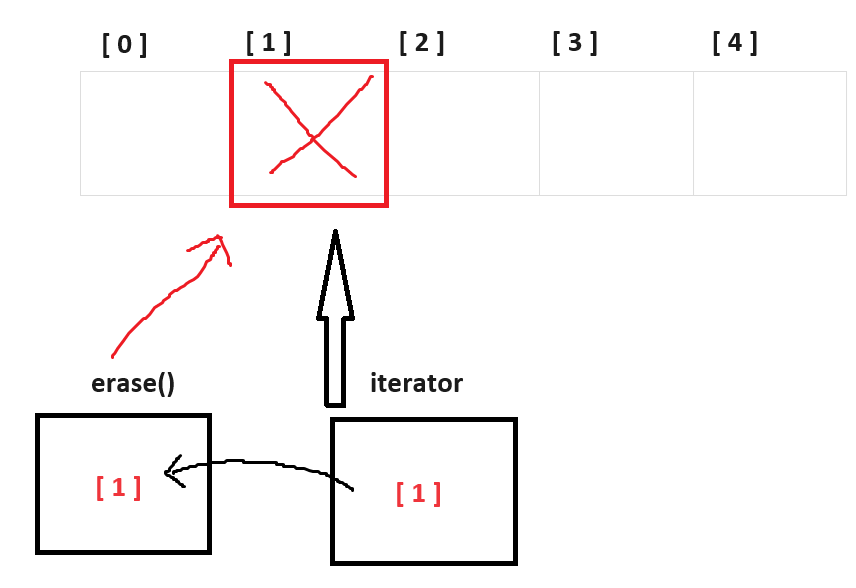
iterator가 가리키는 공간을 erase한테 넘기고
erase는 인자로 받은 공간을 제거하는 방식인 것이죠.
list는 데이터가 따로따로 위치하기 때문에
특정 위치에 접근하려면 비효율적입니다.
결국 하나씩 타고 타고 넘어가면서 접근해야 하기 때문이죠.
그래서 특정 위치에 접근하는 함수가 없습니다.
따라서 특정 위치에 접근하고 싶다면
iterator의 값을 증가시키면서 하나씩 접근해야 하는 것이죠.
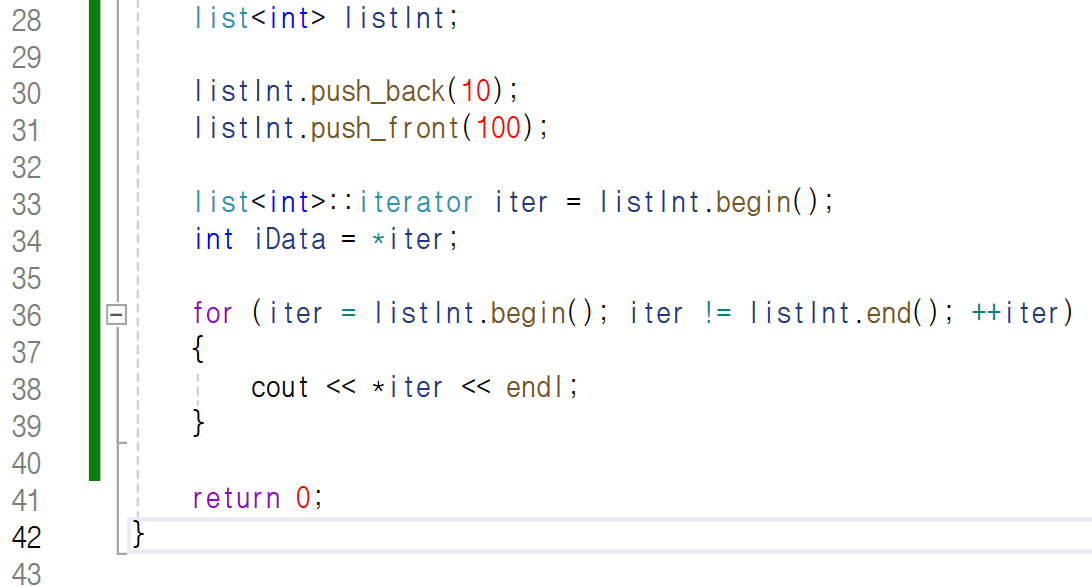
위 코드에서 36번째 줄에 있는
for 문의 초기화 구문부터 보시면
iterator 클래스로 만든 객체 iter에
listInt.begin(), 즉 리스트가 가리키는 첫 번째
노드의 주솟값을 넣고 있습니다.
for 문을 언제까지 반복할 것이냐면,
노드의 주솟값을 저장한 iter의 값과
마지막 노드의 주솟값을 반환하는 listInt.end()의 값이
서로 다를 때까지, 즉 iter의 값과 마지막 주솟값이
같아지는 순간, 마지막 노드에 접근한 것이므로
for 문을 나오죠.
그때까지 iter의 값을 하나씩 올리면서
노드에 하나씩 접근할 것이고, iter에 저장된 주솟값에
접근하여 값을 출력할 것입니다.
생각해 보면
iter의 값과 마지막 주솟값이
같아지는 순간, for 문을 나옵니다.
근데 이렇게 되면 마지막 노드에 있는
데이터는 출력하지 않고 빠져 나가게 되는 것이죠.
하지만 마지막 노드의 값까지 출력되는 것을 보면
end 함수는 마지막 노드의 주솟값을 반환하는 것이 아닌,
마지막 노드의 다음을 반환하는 것임을 알 수 있네요.
이렇게 마지막보다 다음을 가리키는 iterator를
end iterator라고 합니다.
강의 출처 : https://www.youtube.com/watch?v=PFc4g8mxOiI&list=PL4SIC1d_ab-aOxWPucn31NHkQvNPHK1D1&pp=iAQB
'C++ > 기초' 카테고리의 다른 글
| C++ 기초 : iterator (3) (0) | 2024.04.22 |
|---|---|
| C++ 기초 : iterator (2) (0) | 2024.04.20 |
| C++ 기초 : STL (vector와 list) (0) | 2024.04.20 |
| C++ 기초 : namespace와 입출력 구현 (cout, cin) (0) | 2024.04.19 |
| C++ 기초 : 클래스 템플릿을 이용한 리스트 구현 (0) | 2024.04.17 |



