enum class를 추가하여
이진 탐색 트리 역할을 하는 cBST 클래스 템플릿의
insert 함수를 더 간략하게 표현해 봅시다.
enum class인 NODE_TYPE을
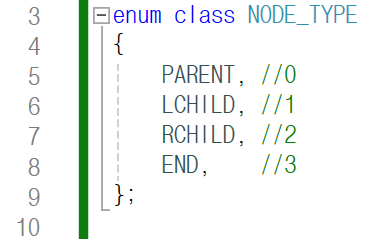
만들어 줍니다.
부모 노드는 0, 왼쪽 자식 노드는 1,
오른쪽 자식 노드는 2로 표현하고 끝은 3으로 표현합니다.
따로 숫자를 대입해 주지 않으면
0부터 시작하여, 1씩 더한 수를 해당 키워드가 할당받게 되죠.
기존 insert 함수에서는
tBSTNode형으로 동적 할당된 공간의
멤버를 하나씩 초기화해 주었죠?
이제는 tBSTNode 클래스 템플릿의
생성자를 만들어서 동적 할당되면서 초기화가
진행될 수 있도록 합시다.

30번째 줄을 보시면
첫 번째 인자로 const tPair<T1, T2>형 레퍼런스를
받습니다. tBSTNode형 객체가 만들어지면
해당 객체는 pair로 이루어지며 인자로 받은 pair의
값을 바꿀 일이 없으므로 const를 붙이고
pair를 복사하여 초기화할 필요 없이
레퍼런스로 바로 참조하여 초기화를 진행하기 위해
레퍼런스로 받는 겁니다.
또한 노드는 자신의 부모 노드와 왼쪽, 오른쪽 자식 노드의
주솟값을 저장하는 멤버를 갖고 있죠? 해당 멤버들을
초기화해 주기 위해 tBSTNode형 포인터 세 개를 받습니다.
( 사실 tBSTNode형 포인터는 typename을 의미하는 T1, T2를
적어 줄 필요가 없습니다. 포인터는 주솟값을
저장하는 변수라 어차피 정수로 표현되기 때문이죠. )
노드가 갖고 있는 pair를 저장하는 멤버, pair는
첫 번째로 받은 인자로 초기화하고 arrNode라는
멤버는 인자로 받은 부모 노드, 왼쪽과 오른쪽 자식 노드의
주솟값으로 초기화를 진행합니다.
23번째 줄을 보시면
기존에 있던 부모 노드, 왼쪽과 오른쪽 자식 노드를
가리키는 멤버를 없애고 tBSTNode형 배열 포인터 arrNode를
추가했습니다. 멤버 arrNode을 통해 세 개의 노드를
한 번에 저장할 겁니다. enum class NODE_TYPE에서 END라는 키워드를
3으로 보기로 하였기 때문에 arrNode[(int)NODE_TYPE::END]는
3칸짜리 배열을 의미합니다. 해당 배열을 tBSTNode형 포인터로
선언하였기 때문에 배열의 각 칸마다 tBSTNode형 포인터가
들어가 있을 겁니다.
tBSTNode 클래스 템플릿의 생성자를 추가하였으니

57번째 줄처럼
바로 초기화가 가능합니다.
새로 동적 할당한 노드는 아직 자리를 잡지 못했으므로
이어진 부모와 자식 노드가 존재하지 않습니다.
그래서 nullptr로 초기화하였고 멤버 pair는 insert 함수를
호출할 때 인자로 받았던 값을 통해 초기화합니다.
if 문은 이진 탐색 트리가 가리키는 루트 노드가
nullptr이면 아무런 노드가 존재하지 않는 것이므로
루트 노드를 가리키는 멤버 pRootNode가
새로운 노드를 가리키게 하는 내용입니다.
이제 본격적으로 enum class에 선언된 키워드를 통해
insert 함수를 조금 더 간략하게 표현해 보죠.
아래 코드에서
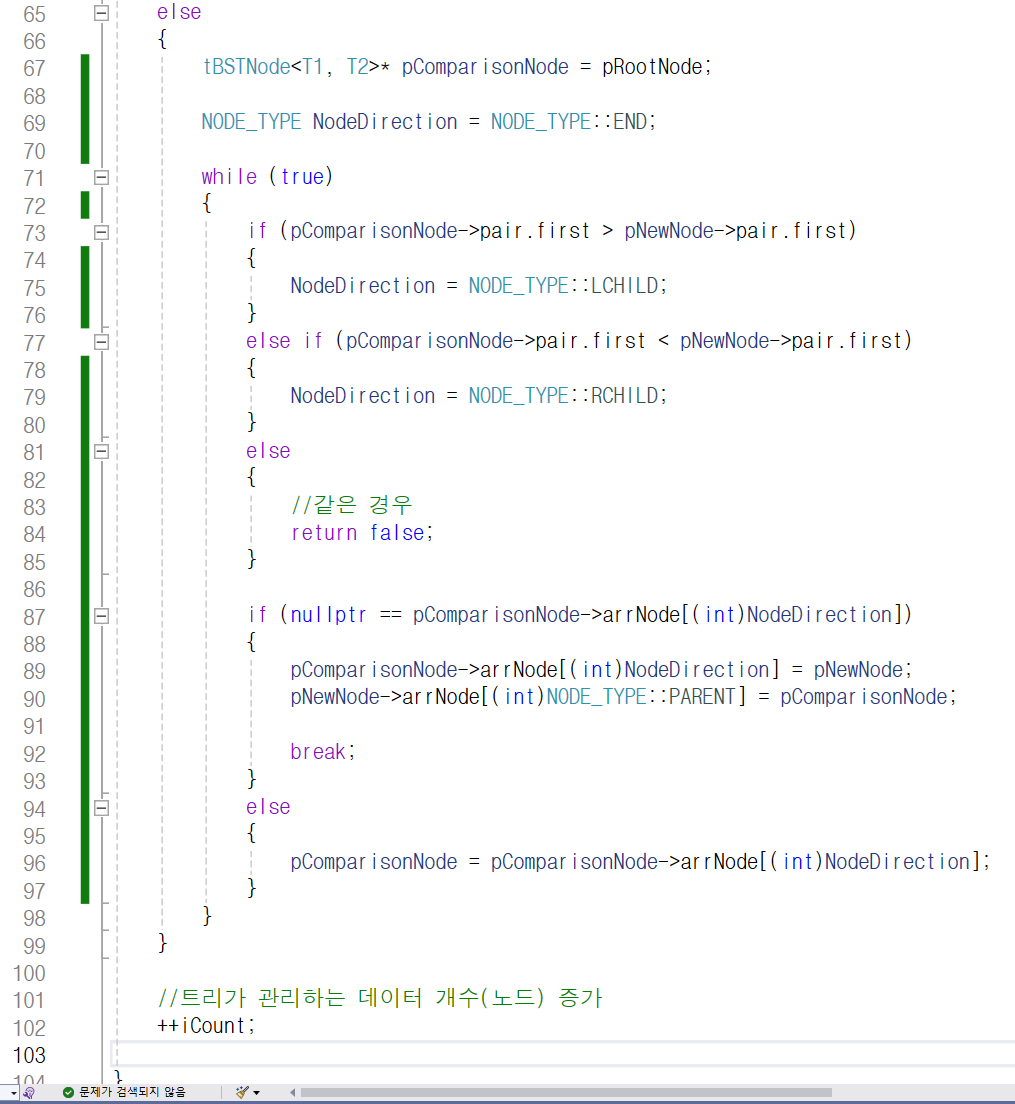
67번째 줄에서
tBSTNode<T1, T2>형 포인터 pComparsionNode에
루트 노드의 주솟값을 저장하고 있습니다.
해당 포인터는 루트 노드부터 시작하여
필요하다면 계속 다음 노드를 가리키게 됩니다.
그래서 pComparsionNode를 통해
새로운 노드와 기존에 있는 노드를 비교할 수 있도록 할 겁니다.
이후 69번째 줄을 봐 주시길 바랍니다.
NODE_TYPE라는 enum class를 통해
NodeDirection이라는 객체를 만들었습니다.
해당 객체를 일단 NODE_TYPE enum 클래스에 있는
END, 즉 3으로 초기화해 줍니다.
while 문에서
73번째 줄은 새로운 노드인 pNewNode가
현재 비교할 노드를 가리키는 pComparsionNode보다
작을 경우 기존에 있는 노드의 왼쪽 자식 노드로
들어가야 하므로 NODE_TYPE형 객체 NodeDirection에
LCHILD, 즉 1이라는 값을 대입합니다.
그렇지 않고 77번째 줄처럼 새로운 노드인 pNewNode가
기존에 있는 노드를 가리키는 pComparsionNode보다
큰 경우 기존에 있는 노드의 오른쪽 자식 노드로
들어가야 하므로 NODE_TYPE형 객체 NodeDirection에
RCHILD, 즉 2라는 값을 대입합니다.
위 두 경우에 해당하지 않는 경우,
즉 기존 노드와 새로운 노드의 값이 같은 경우
insert를 하지 않고 false를 반환합니다.
이제 객체 NodeDirection에는 왼쪽이냐, 오른쪽이냐를
의미하는 값이 대입되어 있을 겁니다.
만약 NodeDirection에 왼쪽을 의미하는 1을 대입되어
있다면 87번째 줄에 있는 if 문을 통해 기존에 있는
노드의 왼쪽 자식이 nullptr인지 확인하게 될 것이고
nullptr이라면 기존 노드의 왼쪽 자식으로 새로 할당한
노드가 들어가게 됩니다. 그리고 새로 할당한 노드에서
부모 노드를 가리키는 멤버 arrNode[0] ( arrNode[(int)NODE_TYPE::PARENT] )에
기존에 있던 노드를 저장하죠.
만약 NodeDirection에 오른쪽을 의미하는 2가 대입되어
있다면 왼쪽이 아닌 오른쪽을 기준으로 진행이 되겠죠?
그리고 whila 문을 빠져 나와
이진 탐색 트리가 관리하는 노드의 개수를 나타내는
iCount의 값을 하나 올리면 insert 함수의 동작은 끝이 납니다.
근데 왼쪽이든 오른쪽이든, 자식 노드가 nullptr이
아니라면, 즉 새로운 노드를 넣으려고 하는데
다른 노드가 이미 존재한다면 현재 비교할 노드를
가리키는 pComparsionNode에 해당 노드를 저장합니다.
그럼 특정 노드를 가리키던 pComparsionNode는
해당 노드의 자식 노드를 가리키게 될 겁니다.
그리고 while 문을 빠져 나가지 않고 다시 반복하면서
pComparsionNode가 가리키는 노드의 자식 노드가 nullptr일 때까지
계속 자식 노드를 가리키며 아래로 내려가겠죠?
그러다가 87번째 줄에 있는 if 문에 걸리는 순간,
즉 pComparsionNode가 가리키는 노드의 자식 노드가 nullptr이어서
새로 할당한 노드가 들어갈 수 있는 순간 while 문을 빠져 나갈 겁니다.
insert 함수를 수정한 뒤에도
잘 작동하는지 확인해 봐야겠죠?

100과 150, 50순으로 pair를 만들고
이를 insert 함수를 통해 이진 탐색 트리에
노드로 넣어 주었습니다.
처음에 100을 넣었기 때문에 이진 탐색 트리 mybst의
멤버 pRootNode는 100이 들어 있는 노드를 가리키고 있네요.
100이 들어 있는 노드가 가리키는 부모 노드, 즉 arrNode[0]의
값을 보니 nullptr입니다. 본인이 루트 노드라서 부모 노드가 존재하지
않기 때문입니다. 또한 왼쪽 자식 노드를 나타내는
arrNode[1]에는 50이 저장된 노드를 저장하고 있습니다.
오른쪽 자식 노드를 나타내는 arrNode[2]에는
150이 저장된 노드를 저장하고 있습니다.
이후 루트 노드의 왼쪽 자식 노드로 가서
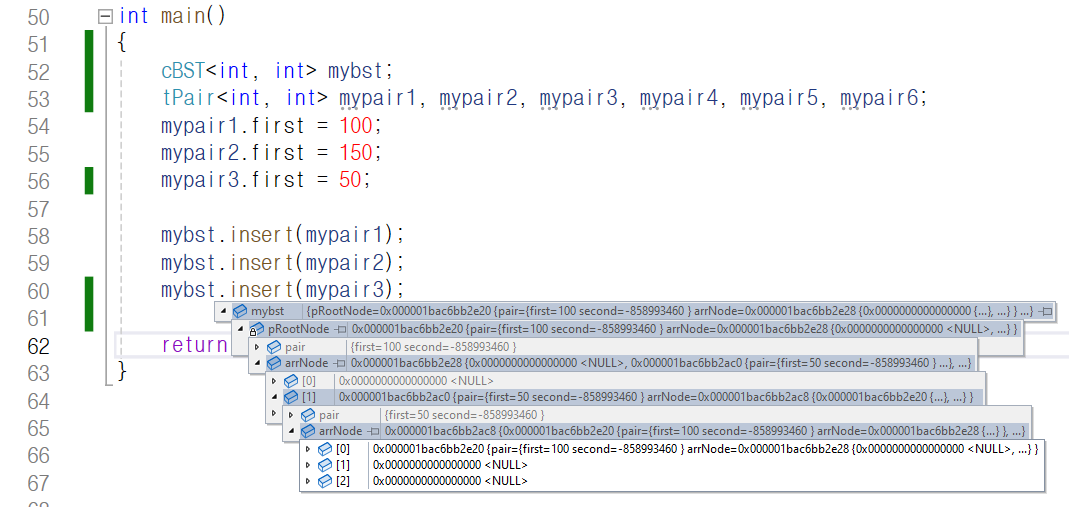
부모 노드를 나타내는 arrNode[0]에는 100이
저장된 노드를 저장하고 있습니다. 또한 왼쪽 자식 노드를
나타내는 arrNode[1]과 오른쪽 자식 노드를 나타내는
arrNode[2]은 nullptr이네요. 자식 노드가 존재하지 않기 때문입니다.
루트 노드의 오른쪽 자식 노드로 가서
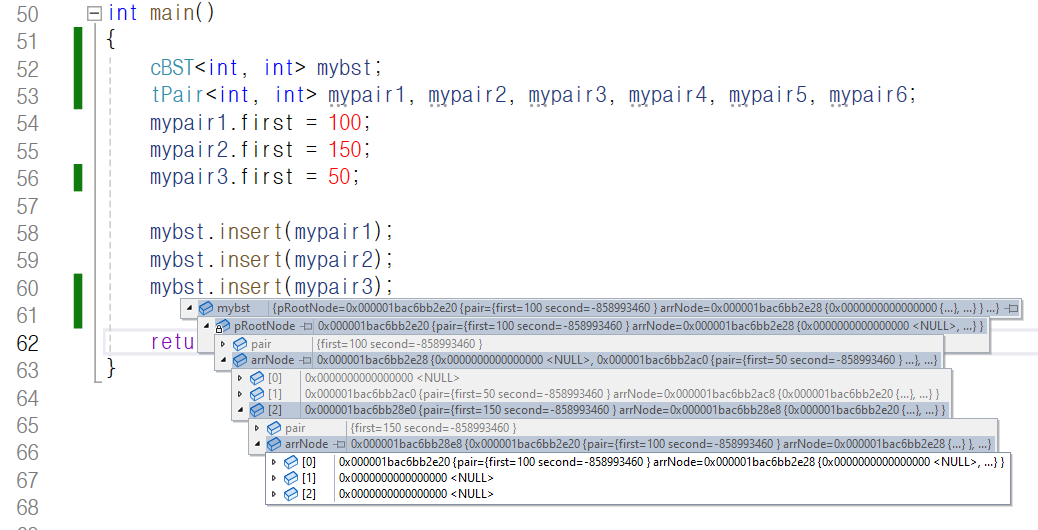
값을 확인해 보니 왼쪽 자식 노드와 마찬가지로
부모 노드로 100이 저장된 노드를 가리키고 있고
자식 노드는 존재하지 않으므로 모두 nullptr이
저장되어 있습니다.
map 클래스로 만든 이진 탐색 트리에 insert 함수를 통해
노드를 삽입할 때를 생각해 봅시다.
make_pair 함수로
값 두 개를 넣어 pair로 묶은 후 노드로 만들었죠?
근데 위 코드에서는 pair 객체를 만들고
해당 객체의 키-값을 나타내는 멤버 first에
값을 직접 넣어 주고 있습니다.
그리고 이것을 insert 함수에 인자로 넣어
이진 탐색 트리의 노드로 삽입하고 있죠.
이렇게 하지 말고 make_pair 함수와 같은
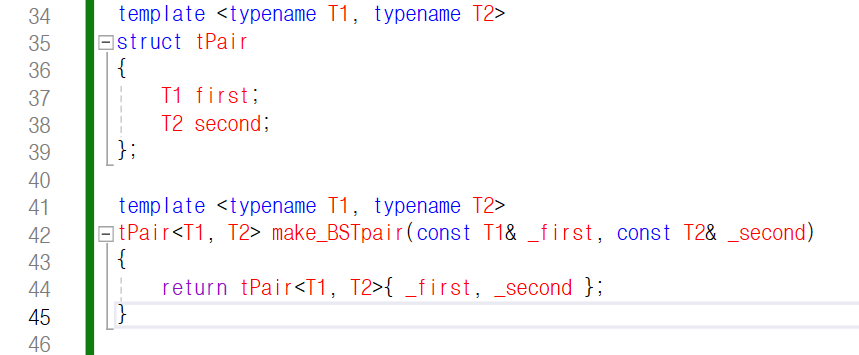
역할을 하는 함수를 구현해 놓겠습니다.
아래 코드를 보시면

28번째 줄에 make_BSTpair라는 함수가
추가되었습니다.
insert 함수는 const tPair형 레퍼런스로 인자를
받기 때문에 make_BSTpair 함수의 반환 타입을
tPair<T1, T2>로 하였습니다.
해당 함수는 인자로 const T1형 레퍼런스와
const T2형 레퍼런스를 받죠.
make_BSTpair 함수를 통해 값을 바꿀 일이
없기 때문에 const가 붙었고, 값을 복사하지 않고
바로 참조하여 복사 비용을 아끼기 위해
레퍼런스로 받는 것이죠.
그리고 인자로 받은 값을 통해
임시 객체를 만들어 바로 반환하고 있습니다.
기존에는 생성자가 없었기 때문에
생성자를 추가해 줘야 합니다.
그래서 22번째 줄에 인자를 두 개 받는
생성자가 추가되었죠. 이니셜라이저를 통해
받은 인자로 두 개의 멤버를 초기화해 줍니다.
만약 생성자를 만들지 않고
make_BSTpair 함수를 만들고 싶다면
위 코드처럼 받은 인자를 통해
바로 구조체로 초기화하여 반환하는 방법도 있습니다.
(tPair는 구조체이기 때문에 이렇게 하는 것도 가능합니다.)
이제 아래 코드처럼
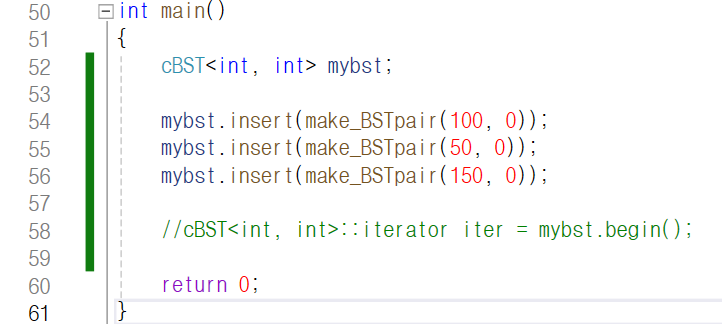
make_BSTpair 함수를 통해 pair를 만들고 이를
이진 탐색 트리에 노드로서 추가할 수 있게 되었습니다.
(second 값은 이진 탐색 트리가 어떻게 구성되는지
알아 보는 상황에서 딱히 의미가 없으므로 0으로 하였습니다.)
map 클래스를 통해 이진 탐색 트리를 구성한 경우에
find 함수를 사용할 때에도 find 함수가 특정 노드를
가리키는 iterator를 반환했다면 값을 찾은 것으로 인지하고,
end iterator를 반환했다면 해당 데이터가 트리 내에
존재하지 않는 것으로 받아들였죠.
그래서 이진 탐색 트리에서 데이터를 찾기 위한
find 함수를 구현하기에 앞서, iterator 클래스를 먼저
만들어야 합니다.
일단 cBST 클래스 템플릿에
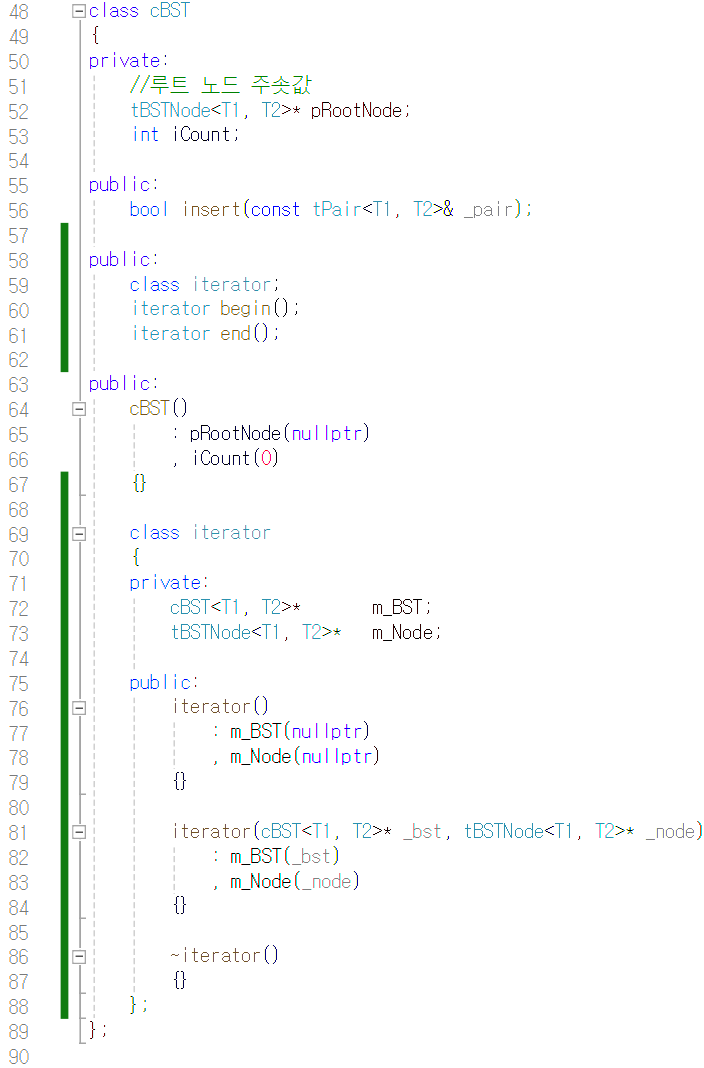
inner 클래스로 iterator 를 만들었습니다.
iterator 는 이진 탐색 트리를 관리하는 BST 를
가리키는 멤버 m_BST 와 노드 자체를 가리키는
멤버 m_Node 를 갖고 있습니다.
그리고 기본 생성자와
BST의 주솟값과 노드의 주솟값, 총 두 개의
주솟값을 인자로 받는 생성자를 만들었습니다.
초기화할 멤버들이 포인터이므로 const로 받거나 레퍼런스로
받으면 오류가 발생합니다. const로 받는다는 것은
BST를 수정하지 않겠다는 의미인데 BST를 가리키는
멤버 m_BST가 const로 선언되지 않았기 때문에 주솟값을 받아
BST를 수정할 수 있는 여지가 생겨 오류가 발생합니다.
또한 레퍼런스로 받는다는 것은
BST를 참조하겠다는 것입니다.
참조를 하면 값을 얻거나 수정을 할 수는 있지만
포인터로 가리키기 위한 주솟값을 얻을 수는 없죠.
m_BST는 BST를 가리키는 포인터이기 때문에
BST의 주솟값으로 초기화해야 하는데 참조를
한다고 주솟값을 얻을 수는 없죠? 만약 레퍼런스로
받고 싶다면 이니셜라이저 부분에서 _bst
앞에 &를 붙여, 참조한 _bst의 주솟값을 얻어 내야 합니다.
그러나 이럴 필요 없이 그냥 포인터로 받으면 되겠죠.
58 ~ 61번째 줄을 보시면
begin 함수와 end 함수가 선언되어 있는 것이
보입니다. 근데 iterator 클래스는 해당 코드보다
밑에 구현되어 있기 때문에 class iterator; 라는
코드를 추가해 iterator라는 클래스가 존재한다고
미리 알려 주어야 반환 타입이 iterator인 begin 함수와
end 함수를 정의할 수 있는 겁니다.
이제 정의 부분을 볼까요?

먼저 begin 함수부터 보시죠.
이진 탐색 트리에서 begin은 어디일까요?
이진 탐색 트리는 중위 순회가 핵심입니다.
중위 순회 기준으로 가장 처음에
순회가 시작되는 노드가 begin이겠죠?
그래서 루트 노드가 아닌
가장 왼쪽 하단에 있는 노드가 begin입니다.
146번째 줄에서 if 문은
begin 함수 호출 시점에 루트 노드가
존재하지 않을 때, 즉 이진 탐색 트리에
아무런 노드가 존재하지 않을 때 end iterator를
반환하기 위한 코드입니다.
그리고 pComparsionNode를 통해
루트 노드부터 시작하여 계속 왼쪽 아래로
이동하면서 처음 노드를 찾아 나갈 겁니다.
pComparsionNode가 가리키는 노드의
왼쪽 자식 노드가 존재한다면 while 문을
반복하는데요, pComparsionNode가 가리키는 노드의
왼쪽 자식 노드가 존재한다면 pComparsionNode가
가리키는 노드를 왼쪽 자식 노드로 교체합니다.
그러다가 pComparsionNode가 가리키는 노드의
왼쪽 자식이 존재하지 않는다면 pComparsionNode가 가리키는 노드가
가장 왼쪽 하단에 존재하는 노드라는 것이므로 while 문을
빠져 나가고 iterator 임시 객체를 반환합니다.
begin 함수를 호출한 BST 자신과
pComparsionNode가 가리키는 노드를
인자로 임시 객체를 만들고 반환합니다.
임시 객체이므로 begin 함수가 종료되면
사라지게 되겠죠. 그래서 begin 함수의
반환 타입을 iterator로 하여 복사가 일어나게
합니다. 그러면 임시 객체가 사라졌어도
main 함수는 임시 객체와 똑같은 값이 복사되어 있는
저장 공간에서 반환된 임시 객체 iterator와
똑같은 값을 가진 iterator를 가져올 수 있죠.
end 함수는 end iterator를 반환하는 함수입니다.
이진 탐색 트리에서 end iterator는 아무런 노드를
가리키지 않는 iterator를 의미하므로 BST 자신과
nullptr을 인자로 하 임시 객체를 만들고 이를 반환하면 되겠죠.
iterator를 만들어
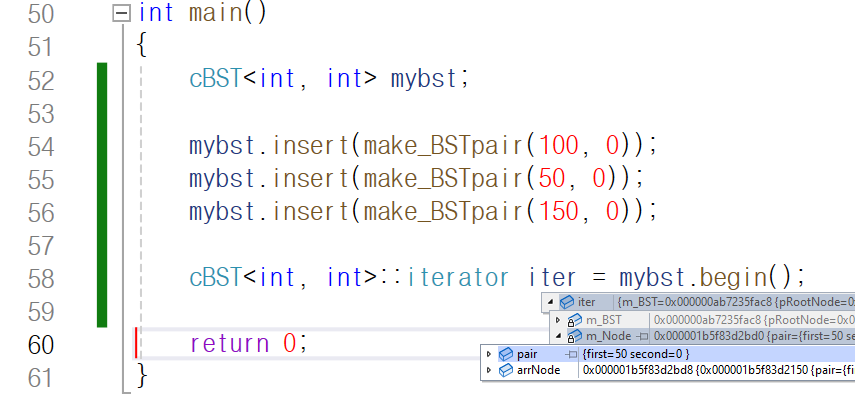
mybst가 관리하는 이진 탐색 트리의 첫 번째 노드,
즉 가장 왼쪽 하단에 위치하는 노드를 대입하였습니다.
정말 키-값이 50인 노드가 iterator에 대입되었습니다.
cBST 클래스 템플릿에 find 함수를 선언하고
클래스 템플릿 외부에 find 함수를 정의하겠습니다.
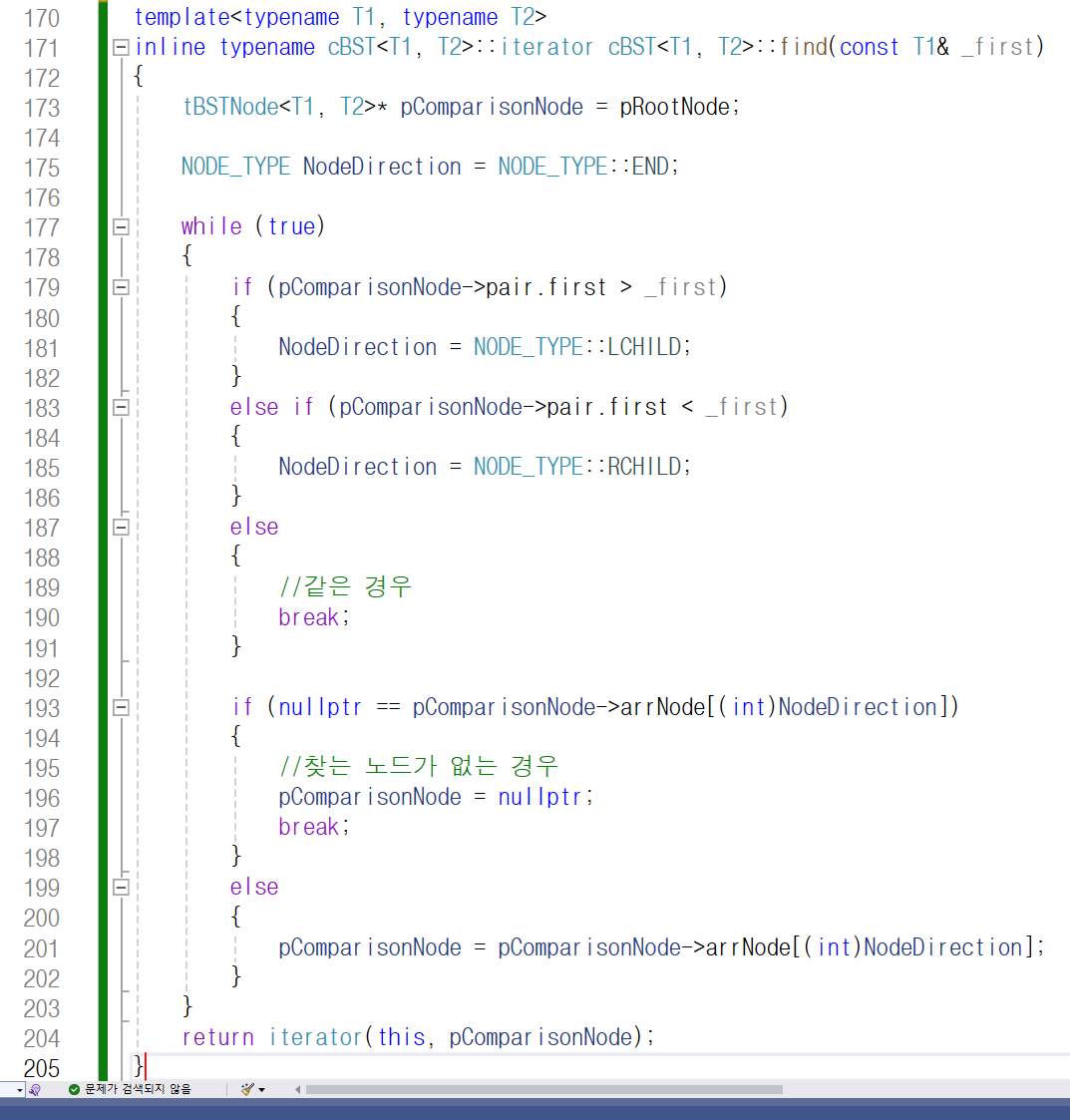
위 코드가 find 함수의 정의입니다.
inline 키워드가 붙어 있습니다.
헤더 파일에서 클래스 또는 클래스 템플릿의
멤버 함수의 선언과 정의를 모두 해 주면
알아서 inline 함수가 됩니다. 그래서 헤더 파일의
멤버 함수의 선언부에서 Ctrl + . 를 입력하여
정의를 만들면 자동으로 inline 키워드가 붙죠.
반환 타입이 iterator인데 컴파일러가 iterator를 인식하지 못합니다.
그래서 typename cBST<T1, T2>::iterator로 써서
cBST<T1, T2>라는 클래스 템플릿에 있는 inner 클래스인
iterator가 반환 타입이라는 것을 명시해 줍니다.
find 함수는 인자로 const T1형 레퍼런스를 받습니다.
노드를 찾으려면 해당 노드의 키-값만 알면 되죠?
그래서 키-값의 자료형인 T형으로 받는 것이고,
find 함수는 단순히 노드를 찾는 함수이기 때문에
값을 바꿀 일이 없어 const를 붙이고 복사 비용을 아끼기 위해
레퍼런스로 받는 것입니다.
동작은 insert 함수와 크게 다르지 않습니다.
결국 특정 노드를 찾기 위해 인자로 받은 값과
루트 노드부터 마지막 노드까지의 값을 비교해
나가야 하기 때문이죠.
차이점이라면 187번째 줄입니다.
find 함수는 인자로 받은 값과
비교하는 노드의 first값(키-값)이 같으면
원하는 노드를 찾은 거죠. 그래서 일단 break를
통해 while 문을 빠져 나갑니다. 이후 find 함수를
호출한 BST 자신과 break를 통해 빠져 나갈 당시의
pComparsionNode가 가리키던 노드를 인자로 하여
iterator 임시 객체를 만들어 반환합니다.
임시 객체이므로 값을 미리 복사해 놓아야
나중에 main 함수에서 복사한 값을 가져와
사용할 수 있겠죠? 그래서 iterator를 반환 타입으로
하여 복사가 발생하도록 합니다.
193번째 줄은 모든 노드를 찾아 봤는데
찾는 노드와 일치하는 노드가 없다면
pComparsionNode가 nullptr을 가리키게 만듭니다.
그리고 break를 빠져 나가죠.
이후 find 함수를 호출한 BST 자신과
break를 통해 빠져 나갈 당시의
pComparsionNode가 가리키던 노드,
즉 nullptr을 인자로 하여 iterator 임시 객체를
만들어 반환합니다. nullptr을 인자로 하여
iterator를 생성하면 해당 iterator는 아무것도
가리키지 않으므로 이는 end iterator로 볼 수 있겠죠?
실행하여 find 함수가 잘 작동하는지
확인하겠습니다.
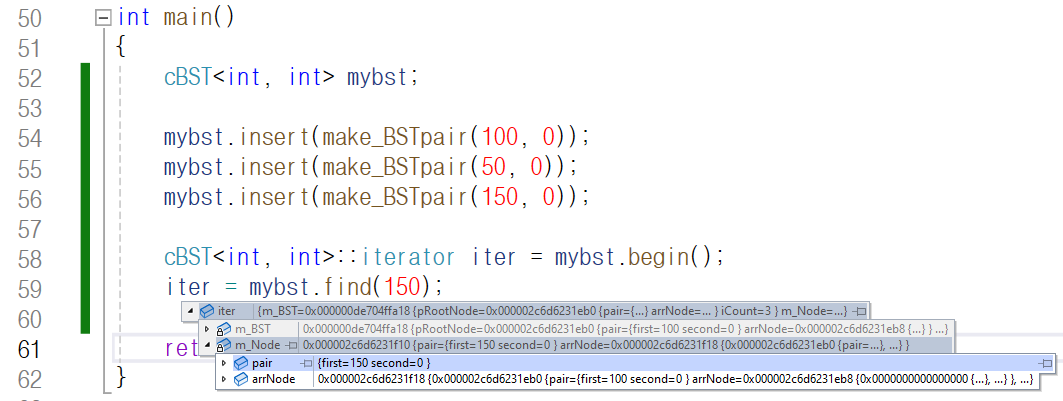
우선 iterator가 중위 순회 기준으로 첫 번째 노드,
즉 키-값이 50인 노드를 가리키게 한 후
find 함수를 통해 키-값이 150인 노드를 찾겠습니다.
해당 노드를 가리키는 iterator를 반환한 후
기존 iterator에 대입하였더니 키-값이
150인 노드를 가리키게 된 것을 확인할 수 있습니다.
이번에는 find 함수를 통해
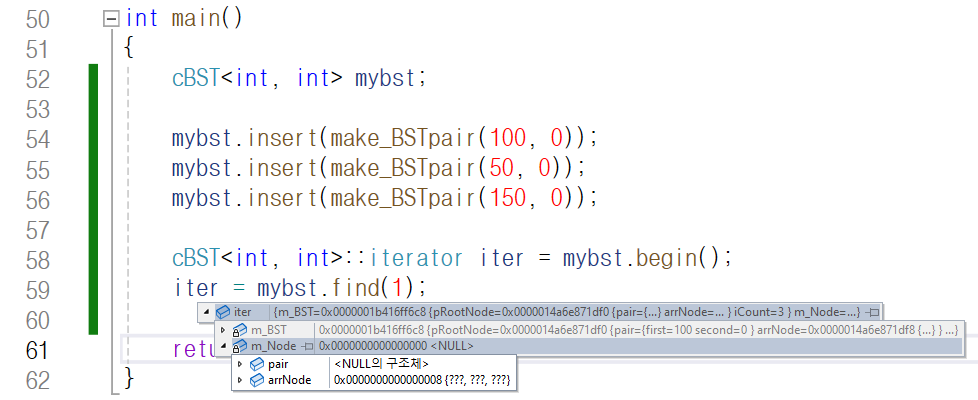
키-값이 1인 존재하지 않는 노드를 찾아 보겠습니다.
해당 노드는 존재하지 않으므로 find 함수는
end iterator를 반환하게 되고 이를 기존 iterator에
대입한 후 값을 확인해 보니 기존 iterator의 값이
nullptr인 것을 확인할 수 있습니다.
강의 출처 : https://www.youtube.com/watch?v=nI7OvpF0y4Q&list=PL4SIC1d_ab-aOxWPucn31NHkQvNPHK1D1&index=77
'C++ > 기초' 카테고리의 다른 글
| C++ 기초 : tree (9) (0) | 2024.05.02 |
|---|---|
| C++ 기초 : tree (8) (0) | 2024.05.01 |
| C++ 기초 : enum (0) | 2024.04.29 |
| C++ 기초 : tree (6) (0) | 2024.04.27 |
| C++ 기초 : tree (5) (0) | 2024.04.27 |



